After reading numerous reports on enterprise AI and adoption rates, I found myself returning to my academic years studying Betriebswirtschaftslehre, the German tradition of enterprise economics and management. That perspective helped me look at AI trough a different lens.

I investigated how organizations are actually adopting AI, where measurable value is emerging, which architectural patterns repeatedly appear in practice, and which governance controls are increasingly required by regulators, cloud providers, and risk-management frameworks. The goal is to analyze AI adoption from the inside out: as an operational, technical, and organizational transformation.
Current state of enterprise AI
Available evidence suggests broad organizational adoption, but uneven operational maturity.
Adoption and operational maturity
According to Stanford HAI’s 2026 AI Index (Source), 88 percent of surveyed organizations in 2025 reported using AI in at least one business function. Additionally, 79 percent reported regular use of generative AI in at least one function.
At the same time, most organizations were still in experimentation or pilot stages, and agent deployment remained early, with no individual business function above 10 percent scaling of AI agents in McKinsey’s 2025 survey (Source).
These figures are global and survey-based, so they are best read as directional rather than as audited market shares.
Economics and measured business impact
The economic picture is real but mixed. Survey respondents increasingly report cost reductions at the use-case or business-unit level.
However, enterprise-wide financial impact remains limited. More than 80 percent of respondents in McKinsey’s 2025 survey said they were not yet seeing a tangible enterprise-level EBIT effect from generative AI. In contrast, 17 percent said at least 5 percent of EBIT in the prior 12 months was attributable to it.
Productivity outcomes and real-world performance
External research also shows that productivity effects vary sharply by task and worker context. Peer-reviewed and academic studies find gains in customer support and professional writing. Yet a randomized 2025 study of experienced open-source developers found slower completion times when frontier coding tools were used on familiar repositories.
The evidence suggests that there is no single defensible average ROI figure for all functions today.
The emerging technology stack
The technical center of gravity is moving toward managed platforms that combine models, retrieval, evaluation, guardrails, logging, and agent orchestration.
Documentation from OpenAI, Google Cloud, AWS, and Microsoft now treats evaluation, document retrieval, tool use, and prompt-injection defenses as standard building blocks rather than as optional add-ons. This aligns with NIST’s AI Risk Management Framework (Source) and its generative AI profile, which emphasize lifecycle-wide governance, measurement, monitoring, human intervention, and incident handling.
Governance, monitoring, and risk controls
In practice, organizations that scale reliably are converging on a narrow set of controls:
- AI-ready data
- Explicit access management
- Benchmarked evaluation sets
- Staged rollouts
- Logging
- Rollback paths
- Role-based human oversight
Regulation and compliance requirements
Regulation is also becoming more operational.
In the EU, parts of the AI Act (Source) are already in force. The regulation requires AI literacy measures and imposes explicit documentation, oversight, logging, data-governance, and impact-assessment duties in defined cases. In the United States, NIST remains the main cross-sector technical guidance source, while the FTC continues to apply ordinary deception and unfairness law to AI-related claims and products.
For most enterprises, this means compliance is no longer just a legal review at the end of the project. Companies should treat it as a design constraint from the start.
Enterprise AI operating model
Adoption
Current adoption is high at the organizational level and much lower at the fully scaled level.
Stanford HAI’s 2026 AI Index (Source), drawing on McKinsey survey data, reports that 88 percent of organizations used AI in at least one business function in 2025 and 79 percent regularly used generative AI in at least one function.
McKinsey’s 2025 State of AI survey (Source) also shows that the majority of organizations remain in experimentation or pilot phases, with only about one-third in scaling and 7 percent fully scaled.
Agentic systems remain earlier still. Only 23 percent of respondents said their organization was scaling an agentic AI system somewhere in the enterprise. Another 39 percent were experimenting, and no individual function exceeded 10 percent scaling.
The pattern is broad exposure, narrow production depth.
Deployment
Deployment is not uniform across enterprise functions. McKinsey reports that risk and compliance, as well as data governance, are often centralized. At the same time, tech talent and adoption are more often hybrid or partially centralized. This is a rational pattern: organizations centralize control where legal and operational consistency matter most, and distribute change where business context matters most.
Output oversight is also uneven. In the same survey, 27 percent of respondents said all generative AI output was reviewed before use, while a similar share said 20 percent or less was checked. Forty-seven percent reported at least one negative consequence from generative AI use. That gap between adoption and control is one of the clearest present-state facts in the market.
Economics
Financial impact is improving, but enterprise-level ROI is still hard to prove. McKinsey reports that, in most business functions, a majority of respondents using generative AI now report cost reductions. Even so, more than 80 percent still report no tangible enterprise-level EBIT effect, which suggests that local productivity wins are not yet consistently translating into firm-wide financial outcomes.
The clearest empirical conclusion on productivity is that effects are task-specific.
In customer support, access to a generative assistant increased productivity by about 15 percent on average, according to this large field study (Source). Less experienced workers saw larger gains.
In a controlled experiment on occupation-specific writing tasks, ChatGPT reduced completion time by 40 percent and increased output quality by 18 percent.
In contrast, a randomized 2025 study of experienced developers working on their own open-source repositories found that AI tool use increased completion time by 19 percent.
This is why neutral reporting should avoid a single average productivity gain claim. Structured, measurable, repetitive tasks tend to show stronger gains than tasks that require deep context, repository-specific knowledge, or hard-to-verify reasoning.
Organizational constraints
Talent and organizational change are now first-order constraints. McKinsey’s 2025 workplace research (Source) reports that:
- Employees are already using generative AI more than leaders estimate.
- Many expect material workflow change within two years.
- Training is one of the most important enablers of adoption.
The EU AI Act reinforces this direction by requiring providers and deployers to take measures to ensure a sufficient level of AI literacy among relevant staff. In practical terms, this becomes a training and operating-model question: Under what rules, with what workflow changes, and with what competence standard?
Potential execution timeline
A typical adoption path (Source) is therefore shorter than traditional enterprise software rollouts, but more iterative after first deployment.
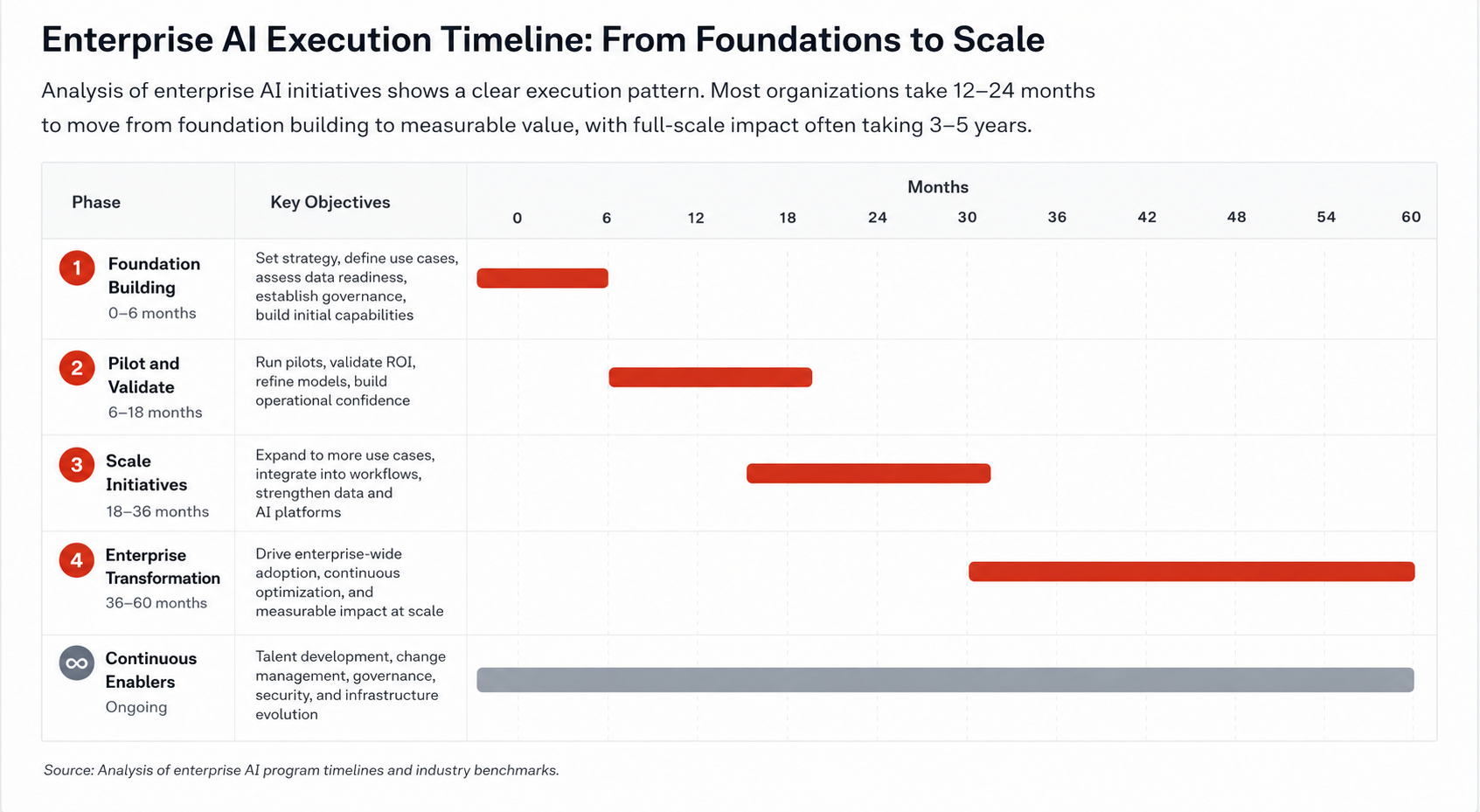
The timeline above is an illustrative synthesis of survey evidence on experimentation and scaling, plus official MLOps guidance that stresses repeated evaluation, deployment, monitoring, and retraining loops.
The operational perspective
Architecture
The dominant application architecture is changing. “Send prompt to model, return answer” is no longer enough. Production systems usually combine at least five layers:
- A model access layer
- An orchestration layer
- A retrieval or data-grounding layer
- Policy and guardrail controls
- An observability layer
Retrieval-augmented generation (RAG) means the model retrieves relevant internal documents or records at runtime and uses them as context. OpenAI’s file search, Amazon Bedrock Knowledge Bases, Vertex AI RAG Engine, and Azure AI Search all formalize this pattern in official documentation.
A primary reason is accuracy: proprietary enterprise data is usually absent from base-model training, so the system must retrieve it at inference time.
Integration
Integration is hard because most enterprise data is not AI-ready by default. Gartner’s 2025 guidance (Source) describes AI-ready data as an ongoing practice rather than a one-time clean-up. It explicitly links success to metadata, data observability, oversight, chunking, embedding, and RAG integration.
Azure AI Search documentation makes the same point from the retrieval side: quality depends on content preparation, chunking, vectorization, hybrid search, semantic ranking, and access control. Vertex AI RAG Engine similarly documents ingestion, transformation, embedding, indexing, retrieval, and grounded generation as distinct stages.
These operational requirements help explain why seemingly simple pilot demos often fail in production.
The operationalization step
MLOps refers to the operational discipline for testing, deploying, monitoring, and updating models and model-driven applications. Official cloud guidance is converging on the same components: reproducible pipelines, repeatable environments, model registry, CI/CD or CI/CD/CT, monitoring for drift, and controlled rollout.
Google documents CI, continuous delivery, and continuous training as the core automation pattern for ML systems. Azure documents reproducible pipelines, reusable environments, model registration, deployment, and metadata tracking as core MLOps functions. For generative systems, this now extends beyond models to prompts, retrieval indexes, evaluators, tool schemas, and agent traces.
Agent systems add another layer of operational complexity. OpenAI’s Responses API and Agents SDK, Microsoft Foundry Agent Service, and Amazon Bedrock AgentCore all package orchestration for multi-step workflows, tool calls, and runtime state. The governance burden is not removed; it transforms into runtime operations.
The strongest operational pattern is therefore to treat agents like software services with permissions, runtime logs, test cases, failure conditions, and rollback plans, not like autonomous staff replacements.
Enterprise AI risk and control framework
Data governance
Data readiness is now one of the main scaling bottleneck.
Gartner (Source) reports that 63 percent of organizations either do not have, or are unsure whether they have, the right data-management practices for AI. It also predicts that through 2026 organizations will abandon 60 percent of AI projects unsupported by AI-ready data.
The same guidance emphasizes representative data, metadata maturity, live production pipelines, and DataOps-style monitoring. This aligns with what the retrieval platforms require in practice: chunking, indexing, vectorization, permission inheritance, network isolation, and refresh workflows.
In other words, data controls are fast becoming upstream systems engineering.
Privacy
Privacy controls differ materially across vendors, which means procurement teams should compare service behavior line by line rather than rely on general brand assurances.
OpenAI states that it does not train models on business data by default, that customers own and control their data, and that enterprise customers can control retention for certain plans.
Microsoft states that Azure OpenAI does not use customer data to retrain models, and its Foundry documentation says customer data, prompts, and completions are not available to OpenAI or other model providers and are not used to train foundation models without explicit permission.
Google Cloud documents a zero-data-retention mode for Vertex AI, but it also documents in-memory caching with a 24-hour TTL by default for published Gemini models unless caching is disabled.
AWS emphasizes shared responsibility, TLS, IAM, activity logging, and that model providers do not have access to Bedrock deployment accounts, prompts, completions, or logs.
Legal review must therefore examine retention, caching, residency, provider access, and support logging as separate questions.
Model risk
Model risk is broader than hallucination.
NIST’s AI RMF defines trustworthy AI in terms that include validity and reliability, safety, security and resilience, accountability and transparency, explainability and interpretability, privacy enhancement, and fairness with harmful bias managed.
NIST also explicitly highlights simulation and in-domain testing, real-time monitoring, and the ability to shut down, modify, or insert human intervention when systems deviate from intended behavior.
That is a widely adopted baseline for objective reporting because it is lifecycle-based and cross-sectoral. It also matches the direction of commercial tooling:
- Bedrock Guardrails supports harmful-content filtering, PII masking, grounding checks, and automated reasoning checks.
- Microsoft Prompt Shields explicitly targets user prompt attacks and document-based indirect attacks.
- Google exposes evaluation and monitoring services as first-class platform features.
Compliance
The regulatory environment is no longer abstract.
In the EU AI Act:
- Article 4 requires providers and deployers to ensure a sufficient level of AI literacy.
- Article 26 requires deployers of high-risk systems to take appropriate technical and organizational measures, assign competent human oversight, ensure relevant and sufficiently representative input data where they control it, monitor operation, suspend use when risk emerges, and retain logs under their control for at least six months in many cases.
- Article 27 requires a fundamental-rights impact assessment before first use in specified cases.
- For general-purpose AI models, Article 53 requires: technical documentation, downstream documentation, a copyright policy, and a sufficiently detailed public summary of training-data content
- For the same general-purpose models, Article 55 adds systemic-risk duties such as model evaluation, adversarial testing, incident reporting, and cybersecurity.
The application timeline is staggered: some obligations already apply, many more apply from August 2026, and further high-risk obligations apply from August 2027. These points are EU-specific, but they affect non-EU firms when the relevant systems or outputs are placed on the EU market or used in the EU.
Outside the EU, the most stable U.S. cross-sector reference remains NIST’s AI RMF and its generative AI profile. The FTC’s enforcement posture is also directly relevant to enterprise buyers and sellers because it continues to apply ordinary consumer-protection rules to deceptive AI claims and harmful AI-enabled products. That means internal review should cover not only technical safety, but also how products are marketed, how capabilities are described, and whether claims are supported by evidence.
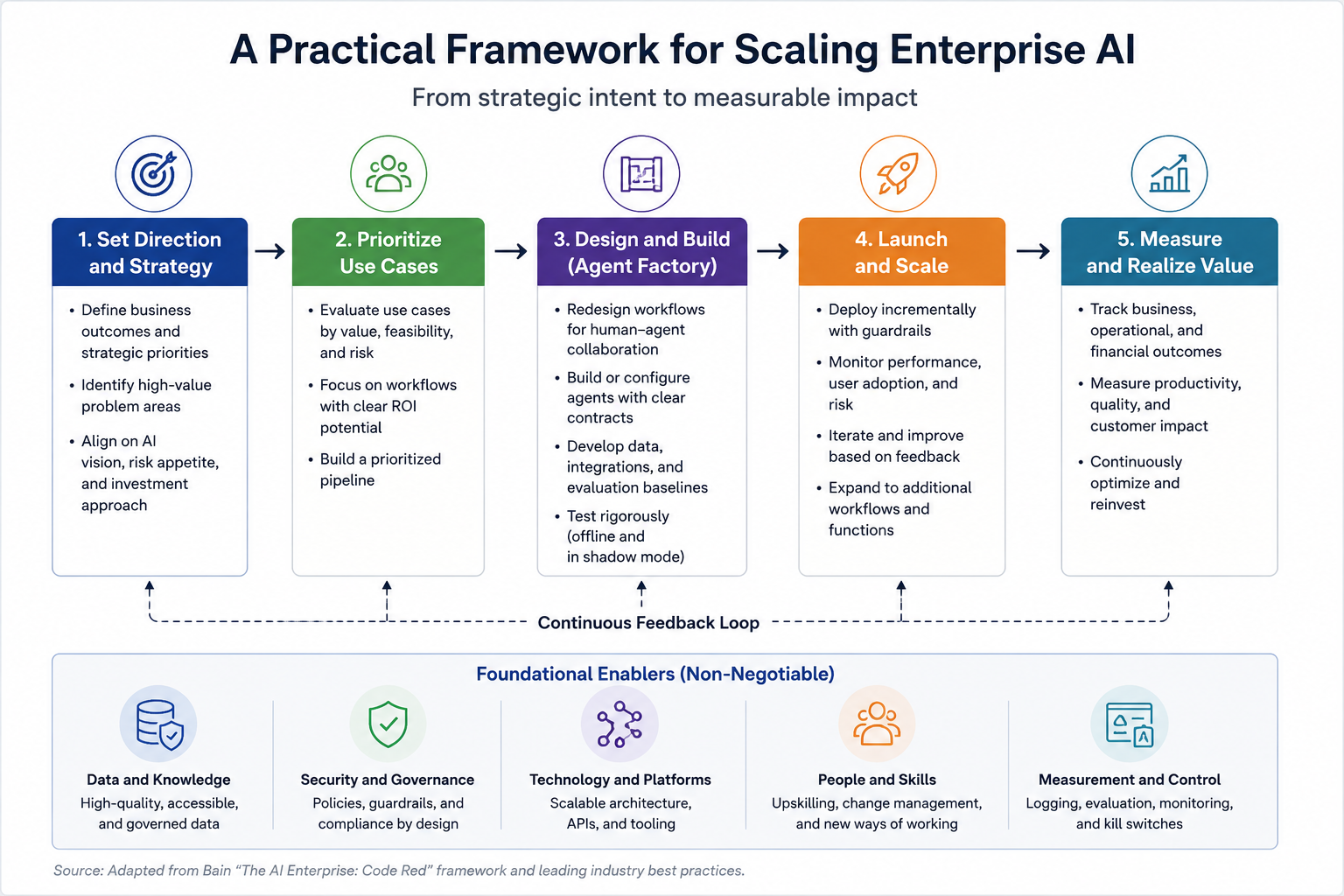
The governance flow above reflects the common control logic that appears across NIST guidance, EU obligations, and current platform design.
Disclaimer: This is not a legal template, but a practical way to connect product, engineering, risk, and compliance teams around one life cycle.
Market and infrastructure outlook
Vendor landscape
Vendor documentation now supports a five-part market view:
- Frontier-model APIs
- Hyperscaler managed AI platforms
- Self-hosted inference stacks
- Retrieval and knowledge layers
- Runtime control layers for safety and evaluation
The market is converging technically even when business models differ. Most major vendors now offer some combination of model access, retrieval, evaluation, orchestration, and guardrail capabilities. But maturity and integration depth still vary significantly.
Deployment choices
Deployment choice is now a policy decision as much as a technical one.
Cloud-first deployment is usually best for speed, model breadth, and managed services. On-prem or self-hosted deployment is strongest when data residency, latency, air-gapped operation, or custom hardware policy dominates. Hybrid is often the practical compromise, especially where retrieval data must stay local but orchestration or model access can remain cloud-managed.
That conclusion is partly an inference from existing product portfolios, but it is directly reflected in the rise of self-hosted inference products and hybrid management planes such as NVIDIA NIM, OpenShift AI, Google Distributed Cloud, and Azure Arc.
Near-term trends
Here are some short-term forecasts, but think of them more as informed inferences. These forecasts are grounded in current product roadmaps, regulatory dates, and market data.
First: Microsoft, AWS, and Google are expanding orchestration and runtime tools for agents in their products.
Second: Evaluation and safety controls will become default buying criteria, not specialist extras, because every major platform now documents model evaluation and guardrail features.
Third: Existing enterprise data platforms will matter more, not less. Gartner predicts that by 2028, 80 percent of generative AI business applications will be developed on existing data-management platforms, reducing delivery complexity and time by 50 percent.
Fourth: Hybrid and sovereignty-oriented deployment will increase because vendors are extending AI into on-prem and edge environments.
Fifth: Compliance work will intensify as the EU AI Act reaches broader application milestones in 2026 and 2027.
Assessing market claims and evidence
Bain’s Code Red report (Source) is most useful as a source of candidate claims, but it should not be treated as a source of final authority. Bain’s published article makes three types of statements:
- Operational practices that can be corroborated
- Directional forecasts that should remain labeled as reported claims
- Strategic taxonomies that should not be presented as standard industry fact
Corroborated practice claim
Bain’s emphasis on a human-calibrated baseline, living evaluation set, shadow rollout, trace logging, real-time visibility, and kill switches is broadly consistent with NIST guidance and with current platform documentation on evaluation, monitoring, and guardrails.
That underlying operating model is supportable. However, the phrase “agent factory” is Bain’s own label, not a standard technical term.
Unverified taxonomy
Bain’s framing of AI as an “enterprise operating system” and its “six deliberate patterns” for scaling are best treated as strategic language and internal taxonomy, not as independently verified market classifications. They can be paraphrased into neutral language, but they should not be stated as settled industry fact.
Reported claim
Bain predicts “30%–50% productivity gains” in most functions from AI agents. That specific range should not be presented as established fact. Independent evidence supports meaningful gains in some settings, but not a universal range across most enterprise functions.
Current academic evidence shows strong heterogeneity by task structure, worker experience, and workflow design.
Several important business outcomes remain hard to verify independently. Most ROI data in today’s market is survey-based, self-reported, or use-case specific rather than audited at enterprise financial-statement level. Vendor documentation is authoritative on product capability and default policy, but it is not independent evidence of realized business impact. Academic productivity findings are informative, but they do not justify one universal value claim across all jobs or all firms.
Primary sources
- Stanford HAI, AI Index 2026, Economy chapter, for current adoption, deployment stages, and labor-market context (Source)
- McKinsey, The State of AI: How organizations are rewiring to capture value (Source) and The State of AI in 2025, for survey data on usage, governance, pilots, scaling, and EBIT impact.
- NIST, AI RMF 1.0 and Generative AI Profile, for lifecycle governance and trustworthiness criteria.
- European Commission / EU AI Act Service Desk and EUR-Lex, for legal obligations and dates of application under Regulation (EU) 2024/1689.
- OpenAI, Google Cloud, AWS, and Microsoft provider documentation, for current platform capabilities, privacy controls, retrieval, evaluation, agents, and guardrails.
- Academic evidence on productivity: QJE field study on customer support (Source), Experimental evidence on the productivity effects of generative artificial intelligence (Source), and the 2025 randomized study on experienced open-source developers (Source).
- FTC regulatory materials (Source), for U.S. guidance on deceptive AI claims and harmful AI-enabled schemes.
Leave a comment